OpenAI 大模型训练的基本原理
在人工智能领域,OpenAI 的大模型(如 GPT 系列)已经成为自然语言处理的重要工具。这些模型通过复杂的训练过程,能够生成高质量的文本内容。本文将简要介绍 OpenAI 大模型训练的基本原理,并通过图文结合的方式进行理解。
1. 基本原理
OpenAI 的大模型基于深度学习中的神经网络架构,尤其是 Transformer。这种架构通过学习大量文本数据中的语言模式和规则,能够理解和生成自然语言。模型的核心是其庞大的参数量,这些参数通过训练过程不断优化,从而捕捉复杂的语言特征。
2. 训练过程
OpenAI 大模型的训练过程通常分为以下几个阶段:
2.1 预训练阶段
在预训练阶段,模型会从海量的文本数据中学习通用的语言模式。这些数据包括互联网上的文章、新闻、书籍等。预训练的目标是让模型掌握语言的基本规则和语义。
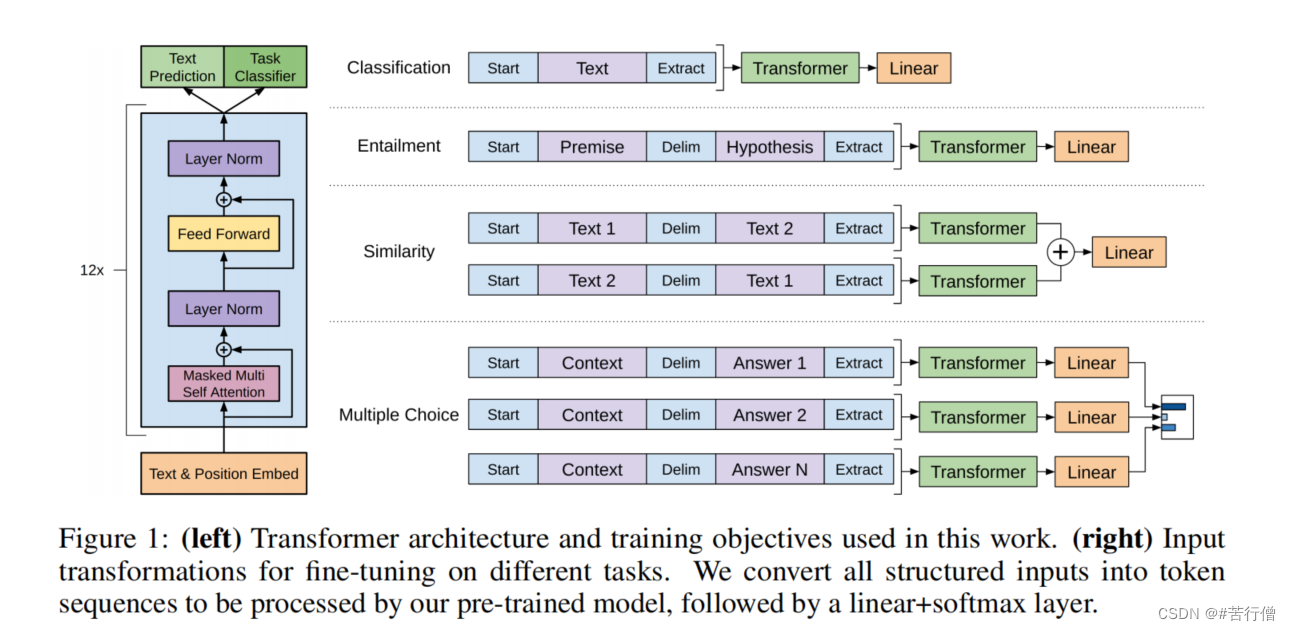 图:Transform 架构示意图
图:Transform 架构示意图
2.2 有监督微调阶段
在预训练的基础上,模型会进入有监督微调阶段。这一阶段使用特定领域的标注数据,对模型进行进一步优化,使其能够更好地适应特定任务。例如,通过微调,模型可以更好地处理问答、翻译或文本生成等任务。
2.3 奖励建模与强化学习阶段
为了进一步提升模型的性能,OpenAI 引入了奖励建模和强化学习。在这一阶段,模型会根据人类标注的偏好数据学习如何生成更高质量的文本。通过强化学习,模型能够根据奖励信号不断优化输出。
3. 关键技术
- Transformer 架构:这是 OpenAI 大模型的核心架构,能够高效处理序列数据。
- 反向传播与梯度下降:通过计算误差并更新模型参数,优化模型性能。
- 参数高效微调:如 LoRA 和 Adapter 等技术,能够在有限的资源下提升模型性能。
4. 总结
OpenAI 的大模型通过预训练、微调和强化学习等多阶段训练过程,能够生成高质量的自然语言文本。其核心在于庞大的参数量和先进的神经网络架构。随着技术的不断发展,这些模型在语言生成、问答和翻译等领域展现出了巨大的潜力。
后面有时间再详细研究Transformer架构和模型微调技术。